EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
図表は全て元論文から引用
Abstract
- 研究目的:
畳み込みニューラルネットワーク(ConvNets)のモデルスケーリングを体系的に研究し、ネットワークの深さ、幅、解像度を適切にバランスさせることでパフォーマンスが向上することを特定する。また、新たなスケーリング方法を提案し、EfficientNetsという新しいモデル群を設計する。
- 方法論:
深さ/幅/解像度の全ての次元を一様にスケーリングする新しい方法を提案し、MobileNetsとResNetのスケーリングにこの方法の有効性を示す。さらに、ニューラルアーキテクチャ検索を使用して新しいベースラインネットワークを設計し、それをスケーリングアップする。
- 結果:
EfficientNetsは、以前のConvNetsよりもはるかに高い精度と効率を達成する。特に、EfficientNet-B7はImageNetで最先端の84.3%のトップ1精度を達成し、最良の既存のConvNetよりも8.4倍小さく、推論が6.1倍速い。また、EfficientNetsはCIFAR-100(91.7%)、Flowers(98.8%)、その他3つの転送学習データセットで最先端の精度を達成し、パラメータは1桁少ない。
- 結論:
ネットワークの深さ、幅、解像度を適切にバランスさせることで、ConvNetsのパフォーマンスが向上することが確認された。また、新たなスケーリング方法とEfficientNetsの設計により、精度と効率の向上が達成された。
Introduction
- ConvNetsのスケーリングアップは、より高い精度を達成するために広く使用されています。例えば、ResNetは、より多くの層を使用してResNet-18からResNet-200にスケーリングアップすることができます。
- しかし、ConvNetsのスケーリングアップのプロセスはまだ十分に理解されておらず、現在では多くの方法が存在します。最も一般的な方法は、深さ(He et al., 2016)または幅(Zagoruyko & Komodakis, 2016)によってConvNetsをスケーリングアップすることです。
- この論文では、ConvNetsのスケーリングアップのプロセスを再考し、より高い精度と効率を達成できる原則的な方法があるかどうかを調査します。
- 著者らの実証研究は、ネットワークの幅/深さ/解像度のすべての次元をバランスさせることが重要であることを示しています。この観察に基づき、著者らは単純だが効果的な複合スケーリング方法を提案します。
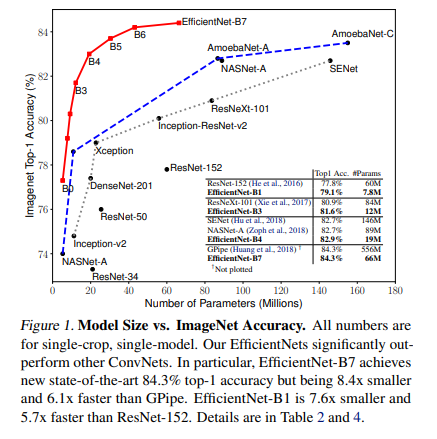
- 著者らのEfficientNetsは、他のConvNetsを大幅に上回ります。特に、EfficientNet-B7は、GPipeの最高精度を上回り、パラメータを8.4倍少なくし、推論で6.1倍速く動作します。
Related Work
- ConvNetの精度:AlexNet(Krizhevsky et al., 2012)が2012年のImageNetコンペティションで優勝して以来、ConvNetsは大きくなることで精度が向上してきました。2014年のImageNet優勝者GoogleNet(Szegedy et al., 2015)は約680万のパラメータで74.8%の精度を達成し、2017年の優勝者SENet(Hu et al., 2018)は1億4500万のパラメータで82.7%の精度を達成しました。最近では、GPipe(Huang et al., 2018)が5億5700万のパラメータを使用して84.3%の精度を達成しました。
- ConvNetの効率:深層ConvNetsはしばしば過剰にパラメータ化されています。モデルの圧縮(Han et al., 2016;He et al., 2018;Yang et al., 2018)は、精度と効率のトレードオフでモデルのサイズを減らす一般的な方法です。最近では、ニューラルアーキテクチャ検索が効率的なモバイルサイズのConvNetsの設計で人気を博しています。
- モデルのスケーリング:ConvNetを異なるリソース制約に対してスケーリングする方法は多くあります。ResNet(He et al., 2016)はネットワークの深さ(#レイヤー)を調整することでスケーリングすることができます。著者らの研究では、ネットワークの幅、深さ、解像度の3つの次元すべてに対してConvNetのスケーリングを系統的かつ経験的に研究します。
Compound Model Scaling
- 著者らは、スケーリング問題を定式化し新しいスケーリング方法を提案します。
- ConvNetレイヤーiは関数Y i = F i (X i )として定義され、F iは演算子、Y iは出力テンソル、X iは入力テンソルを表す。テンソルの形状はH i , W i , C i 1で、H iとW iは空間次元、C iはチャネル次元を示す。

- ConvNet は、レイヤーのリストとして表現され、
![]()
となる。実際には、ConvNetのレイヤーは複数のステージに分割され、各ステージのすべてのレイヤーは同じアーキテクチャを共有する。
- 例えば、ResNetは5つのステージを持ち、各ステージのすべてのレイヤーは最初のレイヤーがダウンサンプリングを行う以外は同じ畳み込みタイプを持つ。
- モデルスケーリングは、ベースラインネットワークで事前に定義されたF iを変更せずに、ネットワークの長さ(L i )、幅(C i )、解像度(H i , W i )を拡大しようとする。
- すべてのレイヤーが一定の比率で均一にスケーリングされるべきであるという制約を設けることで、設計空間をさらに削減する。目標は、与えられたリソース制約の下でモデルの精度を最大化することである。
Scaling Dimensions
- 問題2の主な困難は、最適なd、w、rが相互に依存し、リソース制約により値が変化することです。この困難さから、従来の方法では主にConvNetsの次元を一つだけ拡大しています。
- 深さ(d): 多くのConvNetsが使用する最も一般的な方法です。しかし、深いネットワークは勾配消失問題により訓練が難しくなります。
- 幅(w): 小型モデルに対して一般的に使用されます。しかし、極端に広いが浅いネットワークは、高次元の特徴を捉えるのが難しい傾向があります。
- 解像度(r): 高解像度の入力画像を使用すると、ConvNetsはより細かいパターンを捉える可能性があります。しかし、非常に高解像度では精度の向上が減少します。
- 観察1: ネットワークの幅、深さ、解像度のいずれかの次元を拡大すると精度が向上しますが、大きなモデルでは精度の向上が減少します。

Compound Scaling
- 異なるスケーリング次元が独立していないことを経験的に観察しています。高解像度の画像では、ネットワークの深さを増やすことで、大きな画像の多くのピクセルを含む類似の特徴を捉えることができます。
- また、解像度が高い場合は、ネットワークの幅も増やすべきです。これにより、高解像度の画像のより細かいパターンを捉えることができます。
- これらの直感から、従来の単一次元のスケーリングではなく、異なるスケーリング次元を調整し、バランスを取る必要があることが示唆されます。
- この直感を検証するために、異なるネットワークの深さと解像度での幅のスケーリングを比較しました。結果として、ネットワークの幅をスケーリングするだけでは、精度がすぐに飽和することがわかりました。

- 本研究では、新たな複合スケーリング方法を提案します。これは、複合係数φを用いて、ネットワークの幅、深さ、解像度を一貫してスケーリングします。この方法では、新たなφに対して、全体のFLOPSがおおよそ2φ増加するように制約を設けています。
EfficientNet Architecture
- モデルスケーリングはベースラインネットワークの層演算子Fiを変更しないため、良好なベースラインネットワークを持つことも重要である。既存のConvNetsを用いてスケーリング方法を評価するが、その効果をより明確に示すために、EfficientNetと呼ばれる新しいモバイルサイズのベースラインも開発した。
- (Tan et al., 2019)に触発され、精度とFLOPSの両方を最適化する多目的ニューラルアーキテクチャ検索を利用してベースラインネットワークを開発した。具体的には、(Tan et al., 2019)と同じ検索空間を使用し、ACC(m)×[FLOPS(m)/T] wを最適化目標とした。ここで、ACC(m)とFLOPS(m)はモデルmの精度とFLOPSを示し、Tは目標FLOPS、w=-0.07は精度とFLOPSのトレードオフを制御するハイパーパラメータである。
- ベースラインのEfficientNet-B0から出発し、2つのステップで複合スケーリング方法を適用してスケールアップする。ステップ1では、φ = 1を固定し、2倍のリソースが利用可能であると仮定し、方程式2と3に基づいてα、β、γの小さなグリッド検索を行う。ステップ2では、α、β、γを定数として固定し、方程式3を使用して異なるφでベースラインネットワークをスケールアップし、EfficientNet-B1からB7を得る。
- 大きなモデル周辺で直接α、β、γを検索することでさらに良いパフォーマンスを達成することは可能だが、大きなモデルでの検索コストは禁止的に高くなる。著者らの方法は、小さなベースラインネットワークで一度だけ検索を行い(ステップ1)、その後、他のすべてのモデルで同じスケーリング係数を使用する(ステップ2)ことでこの問題を解決する。
Experiments
- このセクションでは、まず既存のConvNetsと新たに提案されたEfficientNetsに対して、私たちのスケーリング方法を評価します。
- ConvNetsとEfficientNetsの両方に対してスケーリング手法の効果を検証することで、その有効性を確認します。
Scaling Up MobileNets and ResNets
- 著者らのスケーリング方法を初めて広く使用されているMobileNets(Howard et al., 2017; Sandler et al., 2018)とResNet(He et al., 2016)に適用し、その概念証明を行った。
- 表3は、これらを異なる方法でスケーリングしたImageNetの結果を示している。
- 他の単一次元スケーリング方法と比較して、著者らの複合スケーリング方法はこれらのモデルすべての精度を向上させ、著者らの提案するスケーリング方法の一般的なConvNetsに対する有効性を示唆している。

- アンサンブルやマルチクロップモデル(Hu et al., 2018)、または3.5BのInstagram画像で事前学習されたモデル(Mahajan et al., 2018)は省略した。
ImageNet Results for EfficientNet
- 著者らはEfficientNetモデルをImageNetで訓練し、RMSPropオプティマイザー(減衰0.9、運動量0.9)、バッチノーム運動量0.99、重み減衰1e-5、初期学習率0.256(2.4エポックごとに0.97減衰)を使用。
- SiLU(Swish-1)活性化、AutoAugment、確率0.8の確率的深度も使用。大きなモデルでは正則化が必要なため、EfficientNet-B0のドロップアウト比率を0.2からB7の0.5に線形に増加させる。
- 訓練セットからランダムに選んだ25Kの画像をminivalセットとして予約し、このminivalで早期停止を行い、早期停止したチェックポイントを元の検証セットで評価して最終的な検証精度を報告。
- 表2は、同じ基準のEfficientNet-B0からスケーリングされたすべてのEfficientNetモデルのパフォーマンスを示している。EfficientNetモデルは、同等の精度を持つ他のConvNetsよりもパラメータとFLOPSを大幅に少なく使用。

- EfficientNet-B7は、66Mのパラメータと37BのFLOPSで84.3%のtop1精度を達成し、以前の最高のGPipeよりも精度が高く、8.4倍小さい。
- これらの利益は、より良いアーキテクチャ、より良いスケーリング、そしてEfficientNetに特化したより良い訓練設定から得られる。
- 著者らのEfficientNetモデルは小さく、計算も安価である。例えば、EfficientNet-B3は、ResNeXt-101よりも高い精度を達成し、FLOPSを18倍少なく使用。

- 実際のCPU上でいくつかの代表的なCovNetsの推論遅延を測定し、20回の実行の平均遅延を報告。EfficientNet-B1は、広く使用されているResNet-152よりも5.7倍速く、EfficientNet-B7はGPipeよりも約6.1倍速く実行される。
Transfer Learning Results for EfficientNet
- 著者らはEfficientNetを一般的に使用される転移学習データセットに評価しました(表6参照)。訓練設定は(Kornblith et al., 2019)と(Huang et al., 2018)から借用し、ImageNetの事前学習チェックポイントを新しいデータセットで微調整しました。

- 表5は転移学習のパフォーマンスを示しています:(1) NASNet-A (Zoph et al., 2018)やInception-v4 (Szegedy et al., 2017)などの公開モデルと比較して、EfficientNetモデルは平均で4.7倍(最大21倍)のパラメータ削減でより高い精度を達成します。

- (2) DAT (Ngiam et al., 2018)やGPipe (Huang et al., 2018)などの最先端モデルと比較しても、EfficientNetモデルは8つのデータセットのうち5つで彼らの精度を上回り、9.6倍少ないパラメータを使用します。
- 一般的に、EfficientNetsはResNet (He et al., 2016)、DenseNet (Huang et al., 2017)、Inception (Szegedy et al., 2017)、NASNet (Zoph et al., 2018)などの既存モデルよりも、桁違いに少ないパラメータで常により高い精度を達成します。
Discussion
- 提案したスケーリング方法とEfficientNetアーキテクチャの寄与を分離するために、図8は同じEfficientNet-B0基準ネットワークの異なるスケーリング方法のImageNet性能を比較しています。全体的に、すべてのスケーリング方法はFLOPSのコストで精度を向上させますが、提案した複合スケーリング方法は他の単一次元スケーリング方法よりも最大2.5%精度を向上させることができ、提案した複合スケーリングの重要性を示しています。

- 提案した複合スケーリング方法が他の方法よりも優れている理由をさらに理解するために、図7は異なるスケーリング方法を持ついくつかの代表的なモデルのクラス活性化マップ(Zhou et al., 2016)を比較しています。これらのモデルはすべて同じ基準からスケーリングされ、その統計は表7に示されています。画像はImageNet検証セットからランダムに選ばれます。図に示されているように、複合スケーリングを持つモデルは、より関連性の高い領域に焦点を当て、より多くのオブジェクトの詳細を捉える傾向があります。他のモデルはオブジェクトの詳細が不足しているか、画像内のすべてのオブジェクトを捉えることができません。

Conclusion
- この論文では、ConvNetのスケーリングを体系的に研究し、ネットワークの幅、深さ、解像度を適切にバランスさせることが、より高い精度と効率性を阻害する重要な要素であることを特定しました。
- この問題を解決するために、著者らは単純で非常に効果的な複合スケーリング方法を提案し、これによりベースラインのConvNetを任意の目標リソース制約に対して原則的にスケールアップすることが可能になり、モデルの効率性を維持します。
- この複合スケーリング方法により、モバイルサイズのEfficientNetモデルを非常に効果的にスケールアップすることができ、パラメータとFLOPSが桁違いに少ない状態で、ImageNetと5つの一般的に使用される転移学習データセットの両方で最先端の精度を超えることができることを示しました。